
My blog is hosted with CloudFront pointed at an S3 bucket, automatically updated to whenever I push a commit to the GitHub repository containing the sources. Pretty simple in the end, but required a lot of reading AWS blog posts to get set up correctly initially. Now that it's no longer on Cohost, I have the opportunity to look at something I haven't been able to before: numbers. Unfortunately this required reading yet more AWS blog posts.!
Where Do Numbers Come From?
From looking at an automatically-created CloudWatch (AWS's logging/metrics collection service) dashboard, I could see that CloudFront (AWS's CDN service) was already collecting... something...
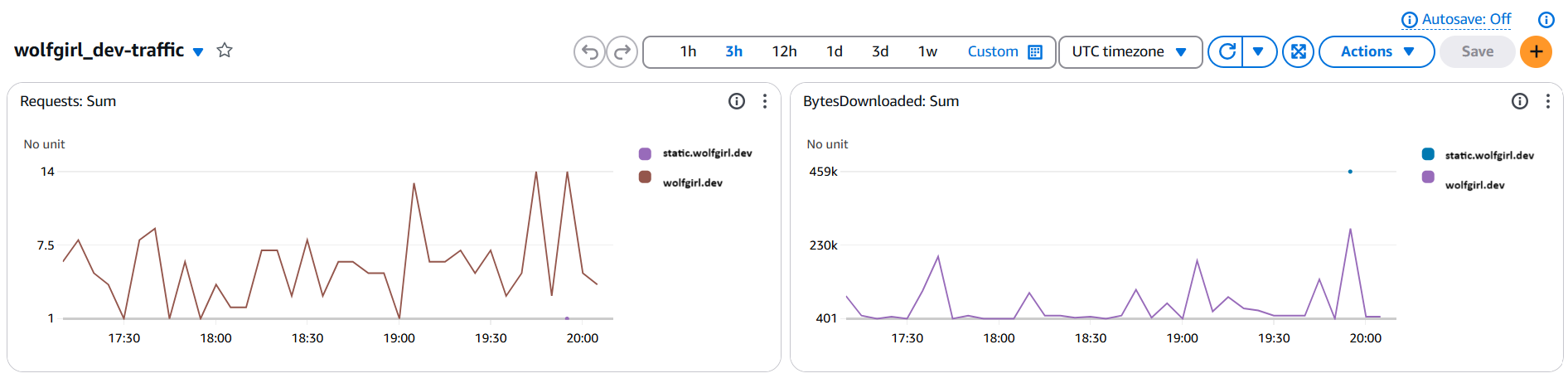
Great! So my website is getting hits! But on what pages? That was the question I wanted answered, and this dashboard would not or could not answer it.
Looking further, I found documentation for how to turn on CloudFront access logs, which would contain the information I wanted in the cs-uri-stem field, among others. The data in CloudWatch currently was just "metrics", not "logs", though. If I wanted to put logs in CloudWatch, it would be... some unknown amount amount of money, based on usage. Given an example on the CloudWatch pricing page, I estimated about $1/mo.
Now that seems pretty reasonable, no? But currently, I pay just $0.10/mo for S3 storage, and nothing for anything else, so logs alone would 10x my costs :(. I am ruthless about making sure I pay as little as possible for the cloud services I use, so this was a non-starter.
Fortunately, there is another option: CloudFront can put its access logs directly into an S3 bucket, which I could analyze & rotate at my own convenience! Except... how?
Where Do Numbers Go?
Initially, I thought "oh, I can just write a hacky Python script to download & parse them all". But then the thought of writing a hacky Python script seemed really unappealing to me, so I lazyweb-ed on Mastodon to see if anyone knew of any pre-built solutions to parse CloudFront logs. Fortunately someone responded (unlobito) suggesting a program called GoAccess1 that looked pretty good. Now, all I had to do was write some hacky Python that calls the following shell script!
#!/usr/bin/env bash
# Make it so if any individual step fails, the script exits early, among other things
set -euo pipefail
# Make it so ** acts as a recursive glob (not default on certain bash-es)
shopt -s globstar
if [[ -z "${AWS_BUCKET_NAME+x}" ]]; then
>&2 echo "Must get bucket passed as AWS_BUCKET_NAME"
exit 1
fi
output_folder="/tmp/${AWS_BUCKET_NAME}"
mkdir -p $output_folder
output_file="/tmp/${AWS_BUCKET_NAME}.html"
touch $output_file
# Download all logs from S3. Must also receive environment variables that allow this to work
aws s3 sync --delete "s3://${AWS_BUCKET_NAME}" "${output_folder}" 1>&2
# Generate the report with GoAccess running inside Docker
zcat "${output_folder}/**/*.gz" | docker run --rm -i -v "${output_file}:/report.html" -e LANG=$LANG allinurl/goaccess -a -o report.html --log-format CLOUDFRONT - 1>&2
echo "${output_file}"GoAccess is pretty fast, and S3 doesn't take that long to download2, so I can get updated reports pretty easily. Now, drumroll please...
What's My Most Viewed Page?
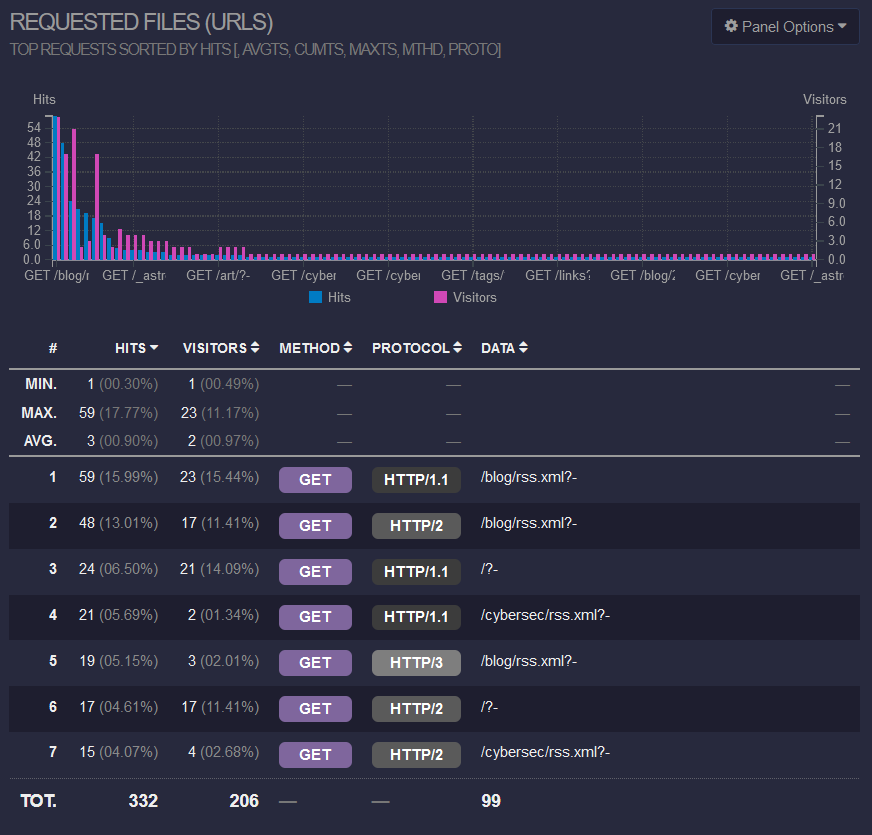
It's RSS.
Guess I have a few readers huh! Hi 👋😸
Other Neat Insights I Didn't Expect
- Firefox is outsize represented (50%) compared to it's overall market share (3%). Y'all are some nerds huh :3
- The "bot problem" (automated vulnerability scanners, other crawlers) isn't quite a big a problem as I thought. RSS traffic is way higher.
- The list of referring sites is pretty interesting; it's mostly feed syndicators, but seeing the range of ones I didn't know about is cool.
I'll try not to abuse my newfound power too hard. Nice to have it available tho.